-
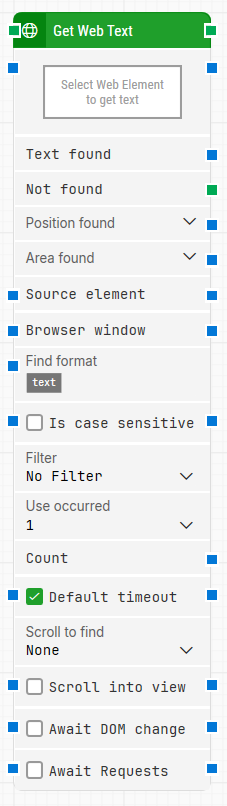
Block header: Shows the current name of the Get Web Text block. You can rename it at any time by double-clicking the header and typing a new title to keep flows readable and organized.
-
Select Web Element to get text: Contains the locator for the web element from which the text should be extracted. This parameter must be set for the block to work.
-
Right-click and select Capture new web element to set the locator.
-
Right-click and select Edit web element to adjust it.
-
Right-click and select Clear web element to remove it.
-
Text found: Contains the text that was found in the selected web element, after applying any Find format and Filter rules.
-
Not found: Triggers if suitable text is not found before the timeout expires. This output is typically used to branch the flow or explicitly fail a case by connecting it to a Fail block.
-
Position found: Returns the browser canvas position where the text was found as X, Y coordinates. The top-left corner of the browser canvas is position 0, 0. Web elements that are not visible (for example, hidden via CSS) report position 0, 0. You can expand this property to work with X and Y separately.
-
Area found: Returns the browser canvas position and size of the found text as X, Y, Width, Height coordinates, starting from the upper-left pixel. The top-left corner of the browser canvas is position 0, 0. Expanding this property lets you use the position and size values individually.
-
Source element: Restricts the search so that the locator only works inside a previously captured source element. For example, if a table web element was found in a previous block, setting that as Source element allows you to search for text only inside that table.
-
Browser window: Specifies which browser window the block should use. If left empty, the default browser window created by Start Web Browser is used.
-
Find format: Defines a text pattern that must be matched for the text to be retrieved. For example, using Status: [TEXT] today means only text inside phrases like Status: Green Mode today is returned, with [TEXT] representing the dynamic part.
-
Is case sensitive: Controls whether the format matching and filter comparisons should be case-sensitive. When cleared (default), matching is case-insensitive.
-
Filter: Applies an additional filter to the extracted text (for example, “Starts with”, “Contains”, as provided in the dropdown). Only text that satisfies this filter is returned.
-
Filter value: Provides the value used by the Filter rule. For example, with a “Starts with” filter, you might set Filter value to Green to keep only text that starts with “Green”.
-
Use Occurrence: Determines which occurrence of matching text to return when more than one match is found:
-
Specific index: use one particular occurrence (for example, the first match).
-
All: iterate through all occurrences. When All is selected, the Current index property and Completed output become available, and the main execution path triggers once per occurrence.
-
Current index: Indicates which occurrence is currently being processed when Use Occurrence = All. If three matches are found, this value will be 1, then 2, then 3 as the block iterates.
-
Count: Contains the total number of text occurrences that match the current settings (locator, format, filter, etc.). This can be used for validation or branching later in the flow.
-
Default timeout: Controls how the timeout is determined:
-
When the checkbox is not selected, the block uses a timeout of 10 seconds, unless you override it via Timeout.
-
When the checkbox is selected, the block uses the Default timeout value defined in the flow settings.
-
Timeout: Sets the maximum time spent searching for the text before giving up and triggering the Not found output. This timeout applies only to this block. Each case also has a separate global timeout configured in the Settings panel; if the case runs longer than that global timeout, it is cancelled regardless of this block’s timeout.
-
Scroll to find: Specifies whether scrolling should be used while searching for text. When a value other than None is selected, the block scrolls through scrollable content (for example, long web pages or infinite-scroll lists) during the search.
-
Max repeats: Defines the maximum number of scroll attempts performed when Scroll to find is enabled. If matching text is not found after this number of scrolls, the search stops.
-
Amount: Sets how far the page should scroll in each scroll attempt when Scroll to find is enabled.
-
Delay (sec): Specifies the delay, in seconds, between scroll attempts when Scroll to find is enabled.
-
Scroll into view: When checked, automatically scrolls the web element that contains the found text into view in the browser window. This is useful for visual verification or for subsequent interactions with that element.
-
Await DOM change: When enabled, delays the search until there have been no changes to the page’s DOM for a specific period (up to a maximum of 30 seconds). This is helpful when background JavaScript updates the page structure; the search starts after the DOM has stabilized or when the maximum wait is reached.
-
Await Requests: When enabled, delays the search until there have been no active XHR (Ajax) requests for a specific period (again with a maximum wait of 30 seconds). This is useful for web applications that perform frequent background requests before rendering or updating content.